import pandas as pdPreprocessing
inspect:road_name별 도로 거리를 추가했습니다.zone: 위, 경도 정사각형 그리드를 생성했습니다.is_slow: 08시부터 21시를 ’느린 시간대’로 지정했습니다.- 명목형 변수를 LabelEncoding 했습니다.
Modeling
- H2O AutoML (링크)
Leaderboard
- Private 3.28871 (120/712, 16.8%)
Preprocessing
data = pd.read_parquet('./train.parquet')
test = pd.read_parquet('./test.parquet')parked = pd.read_csv('./inspect.csv', encoding = 'cp949')
parked = parked.loc[:, ['노선도로명', '거리(Km)']]
parked.columns = ['road_name', 'inspect']
parked = parked.drop_duplicates('road_name')import numpy as np0.01 단위로 위도와 경도를 나누어 격자 변수 grid를 생성했습니다.
lat = np.arange(np.min(data['start_latitude']), np.max(data['start_latitude'])+0.01, 0.01)lon = np.arange(np.min(data['start_longitude']), np.max(data['start_longitude'])+0.01, 0.01)import itertools
def expand_grid(data_dict):
rows = itertools.product(*data_dict.values())
return pd.DataFrame.from_records(rows, columns=data_dict.keys())grid = expand_grid({'lat': lat, 'lon' : lon})get_zone 함수는 grid를 참고하여 위.경도가 속하는 격자 번호를 산출합니다.
def get_zone(lat, lon):
y = (grid
.query('lat > @lat & lon > @lon')
.head(1)
.index.values[0]
)
return yt = (data
.filter(regex = 'latitude|longitude')
.filter(regex = 'start')
.drop_duplicates()
)zone_list = list()for _, row in t.iterrows():
lat = row.start_latitude
lon = row.start_longitude
zone_list.append([lat, lon, get_zone(lat, lon)])zone_info = pd.DataFrame(zone_list, columns=['start_latitude', 'start_longitude', 'zone'])from datetime import datetimele1 = data.groupby('road_name')['target'].mean().sort_values().reset_index(drop = False)
le1['index'] = le1.index.values
le1 = le1.loc[:, ['road_name', 'index']]slow_hour는 심야 시간대가 아닌 시간대입니다.
slow_hour = list(range(8, 21+1, 1))def preprocessing(input: pd.DataFrame, mode: str):
'''
Preprocessing pandas Dataframe.
## Parameters
input: pd.DataFrame which you want to preprocess
mode: ['train', 'test']
## Returns
if mode is train: X_train, X_val, y_train, y_val -> pd.DataFrame
if mode is test: X_test -> pd.DataFrame
'''
# 1000 samples only
# for fast analysis reason
# input = input.sample(n = 1000)
input.base_date = input.base_date.apply(lambda x: datetime.strptime(str(x), '%Y%m%d'))
input['year'] = input.base_date.dt.year
input['month'] = input.base_date.dt.month
input['quarter'] = input.base_date.dt.quarter
input['is_slow'] = input.apply(lambda x: 1 if x.base_hour in slow_hour else 0, axis = 1)
input.base_date = input.base_date.astype(int)
input.road_rating = input.road_rating.astype(str)
input.multi_linked = input.multi_linked.astype(str)
input.multi_linked = input.multi_linked.astype(bool)
input.road_type = input.road_type.astype(str)
input.start_turn_restricted = input.start_turn_restricted.astype(bool)
input.end_turn_restricted = input.end_turn_restricted.astype(bool)
input = input.drop(['id', 'road_in_use', 'vehicle_restricted', 'height_restricted', 'start_turn_restricted', 'multi_linked', 'end_turn_restricted', 'connect_code'], axis = 1)
input = pd.merge(input, parked, how = 'left', on = 'road_name')
input = input.drop_duplicates()
input.inspect[input.inspect.notnull()] = 1
input.inspect[input.inspect.isnull()] = 0
input = input.merge(zone_info, how='left', on = ['start_longitude', 'start_latitude'])
if mode == 'train':
global le1
global le2
global le3
global le4
global le5
global le6
X = input.drop('target', axis = 1)
X['road_name'] = pd.Series(pd.merge(X['road_name'], le1, on = 'road_name').loc[:, "index"], name = 'road_name')
from sklearn.preprocessing import LabelEncoder
le2 = LabelEncoder()
le2.fit(X.day_of_week)
X.day_of_week = le2.transform(X.day_of_week)
le3 = LabelEncoder()
le3.fit(X.road_rating)
X.road_rating = le3.transform(X.road_rating)
le4 = LabelEncoder()
le4.fit(X.road_type)
X.road_type = le4.transform(X.road_type)
le5 = LabelEncoder()
le5.fit(X.start_node_name)
X.start_node_name = le5.transform(X.start_node_name)
le6 = LabelEncoder()
le6.fit(X.end_node_name)
X.end_node_name = le6.transform(X.end_node_name)
y = input['target']
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(X, y, train_size = 0.9, random_state=42)
return X_train, X_val, y_train, y_val
else:
input.road_name = pd.merge(input['road_name'], le1, on = 'road_name').loc[:, "index"]
input.day_of_week = le2.transform(input.day_of_week)
input.road_rating = le3.transform(input.road_rating)
input.road_type = le4.transform(input.road_type)
input.start_node_name = le5.transform(input.start_node_name)
input.end_node_name = le6.transform(input.end_node_name)
X = input
return XX_train, X_val, y_train, y_val = preprocessing(data, 'train')X_test = preprocessing(test, 'test')Modeling
AutoML 패키지인 h2o를 사용했습니다. AutoML은 사용자 개입 없이 일정 수준 이상의 결과를 얻을 수 있습니다. 또한 h2o.explain을 통하여 데이터에 대한 이해도를 높일 수 있습니다.
# Install H2O
!pip install h2oh2o 사용에는 Java가 필요합니다.
!pip install install-jdk==0.3.0# This may show an error if jdk is already installed from a previous run of the notebook,
# but it is OK to proceed
import jdk
jdk.install('11', jre=True)'/root/.jre/jdk-11.0.16.1+1-jre'import os
import subprocessJava 설치 경로를 환경변수로 지정해줍니다.
os.environ['PATH'] = "/root/.jre/jdk-11.0.16.1+1-jre/bin:/usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"subprocess.run('echo $PATH', shell=True, check=True, stdout=subprocess.PIPE, universal_newlines=True)CompletedProcess(args='echo $PATH', returncode=0, stdout='/root/.jre/jdk-11.0.16.1+1-jre/bin:/usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin\n')import h2oh2o.init()Checking whether there is an H2O instance running at http://localhost:54321 ..... not found.
Attempting to start a local H2O server...
Java Version: openjdk version "11.0.16.1" 2022-08-12; OpenJDK Runtime Environment Temurin-11.0.16.1+1 (build 11.0.16.1+1); OpenJDK 64-Bit Server VM Temurin-11.0.16.1+1 (build 11.0.16.1+1, mixed mode)
Starting server from /usr/local/lib/python3.9/dist-packages/h2o/backend/bin/h2o.jar
Ice root: /tmp/tmp36taw0vf
JVM stdout: /tmp/tmp36taw0vf/h2o_unknownUser_started_from_python.out
JVM stderr: /tmp/tmp36taw0vf/h2o_unknownUser_started_from_python.err
Server is running at http://127.0.0.1:54321
Connecting to H2O server at http://127.0.0.1:54321 ... successful.| H2O_cluster_uptime: | 01 secs |
| H2O_cluster_timezone: | Etc/UTC |
| H2O_data_parsing_timezone: | UTC |
| H2O_cluster_version: | 3.38.0.2 |
| H2O_cluster_version_age: | 14 days, 13 hours and 57 minutes |
| H2O_cluster_name: | H2O_from_python_unknownUser_0edfma |
| H2O_cluster_total_nodes: | 1 |
| H2O_cluster_free_memory: | 9.98 Gb |
| H2O_cluster_total_cores: | 6 |
| H2O_cluster_allowed_cores: | 6 |
| H2O_cluster_status: | locked, healthy |
| H2O_connection_url: | http://127.0.0.1:54321 |
| H2O_connection_proxy: | {"http": null, "https": null} |
| H2O_internal_security: | False |
| Python_version: | 3.9.13 final |
train = pd.concat([X_train, y_train], axis = 1)train = h2o.H2OFrame(train)x = list(X_train.columns.values)
y = 'target'from h2o.automl import H2OAutoMLH2OAutoML 파라미터를 지정하여 줍니다. 최대 모델 형태는 5개, 모델 당 60초의 런타임을 지정합니다. MAE(Mean Absolute Error)를 기준으로 모델의 성능을 내림차순 정렬합니다. MAE가 0.01 이상 개선되지 않으면 조기 종료합니다.
aml = H2OAutoML(max_models = 5, max_runtime_secs_per_model=60,
sort_metric='MAE', verbosity='info', stopping_metric='MAE', stopping_tolerance=0.01,
exclude_algos=['DRF'])aml.train(x = x, y = y, training_frame=train)Prediction
aml.leader는 가장 성능이 좋았던 모델의 정보를 가지고 있습니다.
model = aml.leaderh2o_X_val = h2o.H2OFrame(X_val)Parse progress: |████████████████████████████████████████████████████████████████| (done) 100%pred = model.predict(h2o_X_val)stackedensemble prediction progress: |███████████████████████████████████████████| (done) 100%pred = np.array(pred.as_data_frame().loc[:, 'predict'])from sklearn.metrics import mean_absolute_errorval = pd.concat([X_val, y_val], axis = 1)val = h2o.H2OFrame(val)Parse progress: |████████████████████████████████████████████████████████████████| (done) 100%h2o에는 몇가지 유용한 설명 함수가 있습니다.
residual_analysis_plot은 예측값과 실제값 사이의 잔차 분포를 볼 수 있습니다. 타겟 변수 분포에 따라 어떤 예측을 보였는지 확인할 수 있습니다.
model.residual_analysis_plot(val)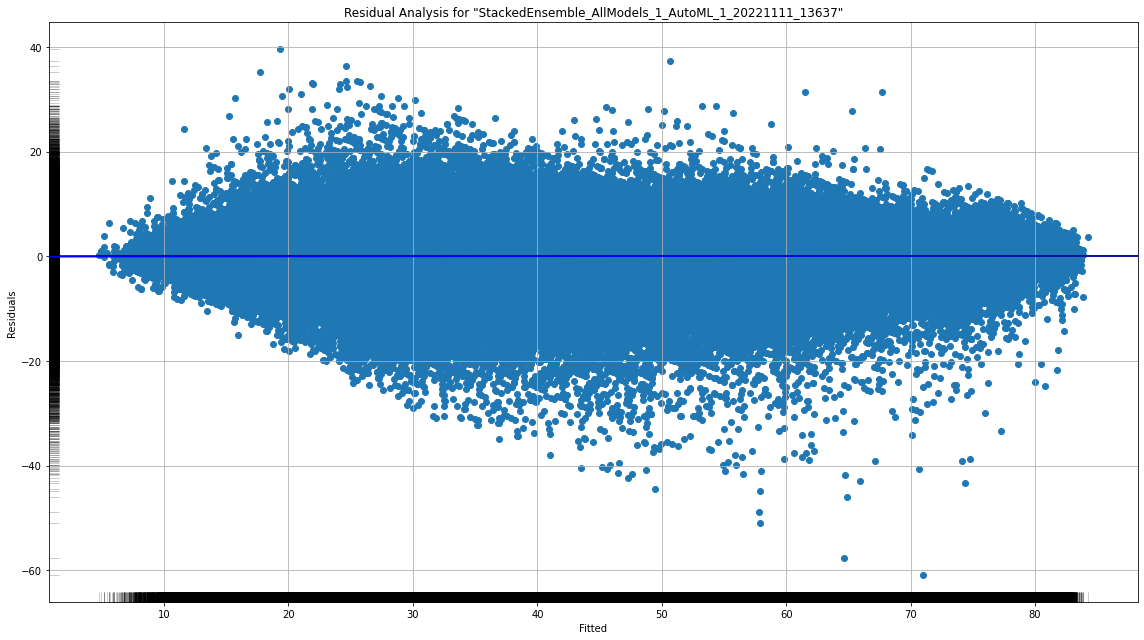
aml.varimp 는 변수 중요도를 산출합니다. 어떤 변수가 예측 문제에 가장 도움이 되었는지 보여주는 함수입니다. 아래에서는 maximum_speed_limit의 중요도가 모델에 관계없이 가장 큰 것을 알 수 있습니다.
va_plot = aml.varimp_heatmap()
aml.leaderboard| model_id | mae | rmse | mse | rmsle | mean_residual_deviance |
|---|---|---|---|---|---|
| StackedEnsemble_AllModels_1_AutoML_1_20221111_13637 | 3.00385 | 4.33997 | 18.8353 | 0.136033 | 18.8353 |
| StackedEnsemble_BestOfFamily_1_AutoML_1_20221111_13637 | 3.00572 | 4.34043 | 18.8394 | 0.136143 | 18.8394 |
| GBM_1_AutoML_1_20221111_13637 | 3.04496 | 4.38972 | 19.2697 | 0.138128 | 19.2697 |
| XGBoost_1_AutoML_1_20221111_13637 | 3.04607 | 4.39172 | 19.2872 | 0.136864 | 19.2872 |
| XGBoost_2_AutoML_1_20221111_13637 | 3.20189 | 4.56481 | 20.8375 | 0.142696 | 20.8375 |
| GBM_2_AutoML_1_20221111_13637 | 3.77482 | 5.17977 | 26.83 | 0.162599 | 26.83 |
| GLM_1_AutoML_1_20221111_13637 | 9.72862 | 12.0894 | 146.153 | 0.335651 | 146.153 |
[7 rows x 6 columns]
위에서 Stacked Ensemble의 성능이 가장 좋았던 것을 확인할 수 있습니다. 추가적인 h2o.explain 기능을 활용하기 위해서 Tree 계열의 모델인 Gradient Boosting을 m 이라는 변수로 가져오겠습니다.
m = h2o.get_model('GBM_1_AutoML_1_20221110_31701')model.varimp는 위에서 본 변수 중요도와 같습니다.
m.varimp(train)| variable | relative_importance | scaled_importance | percentage | |
|---|---|---|---|---|
| 0 | end_longitude | 908544512.0 | 1.000000 | 0.185783 |
| 1 | maximum_speed_limit | 813737280.0 | 0.895649 | 0.166396 |
| 2 | road_rating | 548949696.0 | 0.604208 | 0.112251 |
| 3 | start_longitude | 484623360.0 | 0.533406 | 0.099098 |
| 4 | end_latitude | 437984480.0 | 0.482073 | 0.089561 |
| 5 | zone | 415906144.0 | 0.457772 | 0.085046 |
| 6 | base_hour | 351637056.0 | 0.387033 | 0.071904 |
| 7 | start_latitude | 313349824.0 | 0.344892 | 0.064075 |
| 8 | lane_count | 162403920.0 | 0.178752 | 0.033209 |
| 9 | end_node_name | 130844344.0 | 0.144015 | 0.026756 |
| 10 | start_node_name | 126941728.0 | 0.139720 | 0.025958 |
| 11 | base_date | 83674040.0 | 0.092097 | 0.017110 |
| 12 | road_type | 29916160.0 | 0.032928 | 0.006117 |
| 13 | weight_restricted | 29856938.0 | 0.032862 | 0.006105 |
| 14 | inspect | 29272602.0 | 0.032219 | 0.005986 |
| 15 | day_of_week | 15285578.0 | 0.016824 | 0.003126 |
| 16 | connect_code | 4495931.0 | 0.004948 | 0.000919 |
| 17 | road_name | 2939106.0 | 0.003235 | 0.000601 |
learning_curve_plot은 반복횟수에 따른 모델 개선 정도를 나타냅니다. 개선이 잘 되지 않는 부분부터는 Overfitting이 일어날 수 있습니다.
learning_curve_plot = model.learning_curve_plot()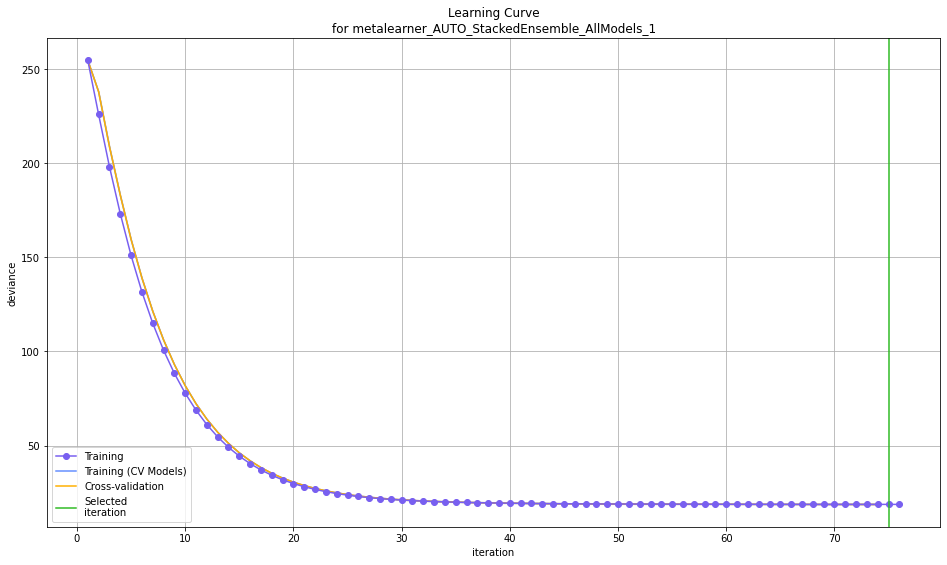
learning_curve_plot = m.learning_curve_plot()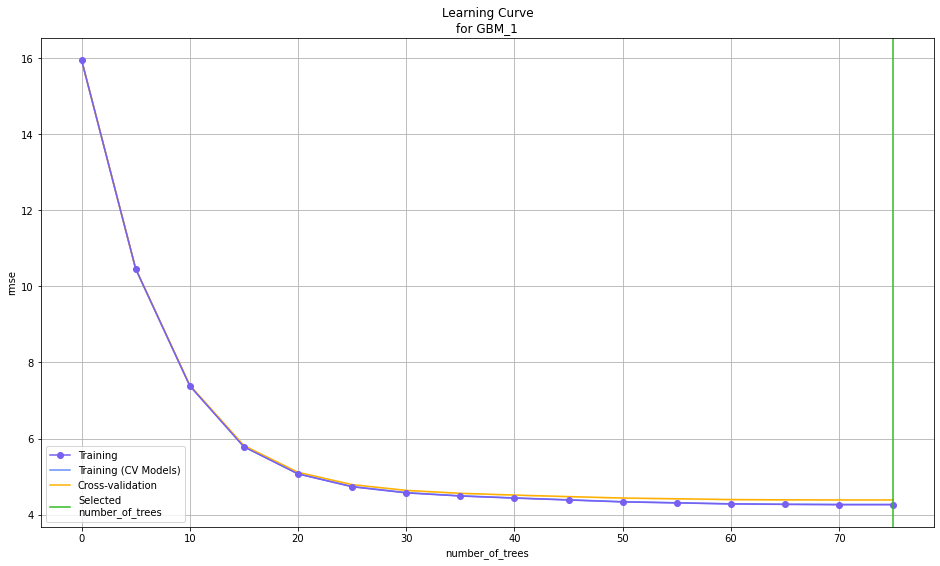
shap_explain_row_plot은 변수 중요도의 또 다른 해석으로 볼 수 있습니다. 행 별로 prediction 값을 산출하는 데 가장 영향이 컸던 변수를 확인할 수 있습니다. 지리 정보가 있는 end_longitude, zone 등은 예측값이 커지는 것에 기여를 했고, 시간 변수인 base_hour는 예측값이 적어지는 데 가장 큰 기여를 했습니다. base_hour가 17시이니 이러한 설명은 합리적이라고 말할 수 있겠죠.
m.shap_explain_row_plot(train, row_index = 0)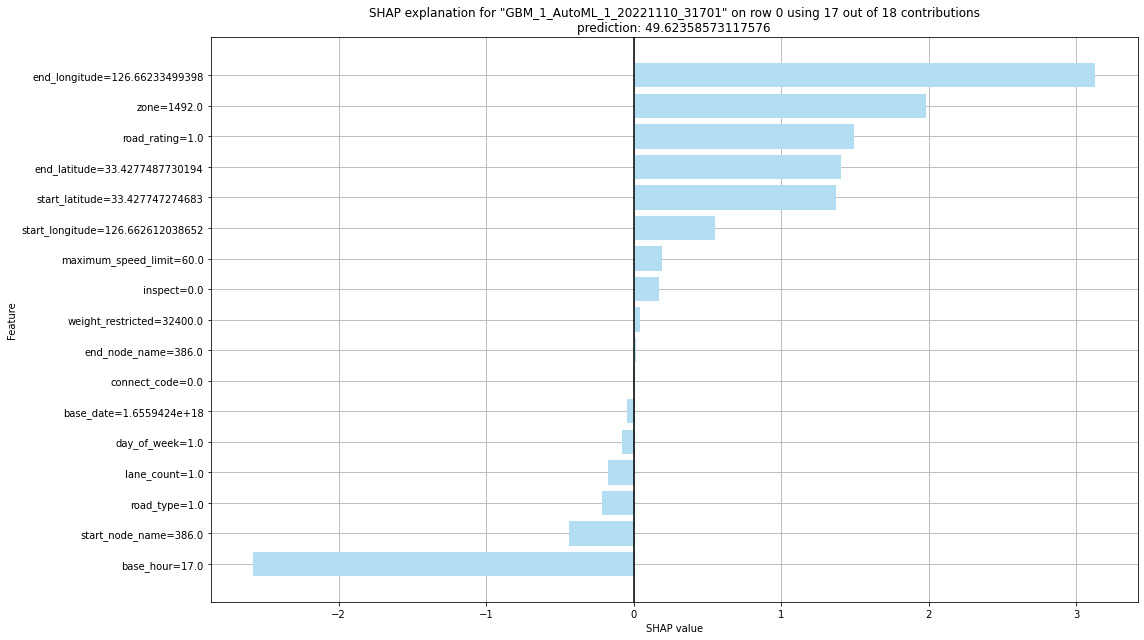
아래와 같이 h2o.save_model을 통해 모델을 저장하고 나중에 다시 활용할 수 있습니다.
h2o.save_model(model=model, path='./',force = True)'/notebooks/StackedEnsemble_AllModels_1_AutoML_1_20221110_31701'h2o.save_model(model=m, path='./',force = True)'/notebooks/GBM_1_AutoML_1_20221110_31701'h2o_test = h2o.H2OFrame(X_test)Parse progress: |████████████████████████████████████████████████████████████████| (done) 100%아래 코드로 제출을 위한 prediction을 만들고, submission 양식에 맞게 저장하겠습니다.
pred = aml.leader.predict(h2o_test)stackedensemble prediction progress: |███████████████████████████████████████████| (done) 100%pred = np.array(pred.as_data_frame().loc[:, 'predict'])sample_submission = pd.read_csv('./sample_submission.csv')sample_submission['target'] = pred
sample_submission.to_csv("./submit.csv", index = False)sample_submission| id | target | |
|---|---|---|
| 0 | TEST_000000 | 25.774575 |
| 1 | TEST_000001 | 40.695041 |
| 2 | TEST_000002 | 65.419437 |
| 3 | TEST_000003 | 39.285973 |
| 4 | TEST_000004 | 42.577536 |
| ... | ... | ... |
| 291236 | TEST_291236 | 47.951427 |
| 291237 | TEST_291237 | 50.379779 |
| 291238 | TEST_291238 | 21.550416 |
| 291239 | TEST_291239 | 24.027667 |
| 291240 | TEST_291240 | 46.686936 |
291241 rows × 2 columns