from fastai.vision.all import *- How is a grayscale image represented on a computer? How about a color image?
이미지는 가로와 세로의 픽셀로 이루어져 있습니다. 흑백 이미지는 각 픽셀의 강도에 따라 희고 검은 점의 집합으로 나타납니다. 0인 경우 흰색, 255은 검은색으로 나타납니다. 컬러 이미지는 픽셀 강도를 나타내는 하나의 값이 아닌 빨강, 초록, 파란색의 조합입니다. 따라서 흑백 이미지와 같은 2차원 텐서가 색깔별로 중첩된 모습입니다.
- How are the files and folders in the MNIST_SAMPLE dataset structured? Why?
MNIST_SAMPLE은 train, valid, labels.csv로 구성되어 있습니다.
train, valid 폴더는 각각 숫자 이미지를 담고 있는데, train 폴더에 있는 이미지로 모델을 훈련하고 valid에 있는 이미지로 검증하는 것이 보통입니다.
labels.csv는 파일의 경로와 레이블이 들어가 있어 경로 이미지를 따라 사진을 가져오고, 해당 이미지의 레이블을 파악할 수 있는 구조입니다.
(아래 코드 참조)
path = untar_data(URLs.MNIST_SAMPLE)
100.14% [3219456/3214948 00:03<00:00]
Path('/home/hykim/.fastai/data/mnist_sample')path = Path('/home/hykim/.fastai/data/mnist_sample')(path).ls()(#3) [Path('/home/hykim/.fastai/data/mnist_sample/train'),Path('/home/hykim/.fastai/data/mnist_sample/labels.csv'),Path('/home/hykim/.fastai/data/mnist_sample/valid')]import pandas as pdlabels = pd.read_csv(path/'labels.csv')(path/'train/3').ls()(#6131) [Path('/home/hykim/.fastai/data/mnist_sample/train/3/17471.png'),Path('/home/hykim/.fastai/data/mnist_sample/train/3/46130.png'),Path('/home/hykim/.fastai/data/mnist_sample/train/3/49183.png'),Path('/home/hykim/.fastai/data/mnist_sample/train/3/20797.png'),Path('/home/hykim/.fastai/data/mnist_sample/train/3/19230.png'),Path('/home/hykim/.fastai/data/mnist_sample/train/3/45636.png'),Path('/home/hykim/.fastai/data/mnist_sample/train/3/52539.png'),Path('/home/hykim/.fastai/data/mnist_sample/train/3/43562.png'),Path('/home/hykim/.fastai/data/mnist_sample/train/3/43198.png'),Path('/home/hykim/.fastai/data/mnist_sample/train/3/5354.png')...]- Explain how the “pixel similarity” approach to classifying digits works.
실제 ’3’인 숫자 이미지 집합에서 각 픽셀의 강도 평균을 구할 수 있습니다.
- What is a list comprehension? Create one now that selects odd numbers from a list and doubles them.
List Comprehension은 리스트와 반복문 추가 없이도 계산 처리 및 리스트에 저장이 가능한 파이썬의 기술입니다.
[i for i in range(1, 10+1) if i % 2 == 1][1, 3, 5, 7, 9]- What is a “rank-3 tensor”?
rank-3 텐서는 차원의 값이 3인 텐서입니다. rank-3 텐서의 원소에 접근하기 위해서는 3개의 슬라이싱 인덱스가 필요합니다.
- What is the difference between tensor rank and shape? How do you get the rank from the shape?
shape는 텐서의 구조를 의미합니다. len(shape)의 값이 rank를 의미합니다.
- What are RMSE and L1 norm?
RMSE는 Root Mean Squared Error로, L2 norm으로도 불립니다. 예측값과 실제값의 차에 제곱한 값의 평균입니다. L1 norm은 Mean Squared Error와 동일합니다. 예측값과 실제값의 차의 절댓값의 평균입니다.
- How can you apply a calculation on thousands of numbers at once, many thousands of times faster than a Python loop?
numpy, pytorch 내부 함수를 활용해야 합니다. C++ 위에서 구현되어 기존 파이썬에 비해 1000배 이상 빠릅니다.
- Create a 3×3 tensor or array containing the numbers from 1 to 9. Double it. Select the bottom-right four numbers.
import torch
(torch.tensor(range(1, 9+1)).reshape((3,3))*2)[1:, 1:]tensor([[10, 12],
[16, 18]])- What is broadcasting?
브로드캐스팅은 각 텐서의 랭크가 다를 때 적은 랭크를 가진 변수를 늘리어 큰 랭크에 연산하는 방법입니다.
- Are metrics generally calculated using the training set, or the validation set? Why?
메트릭은 주로 Validation set을 기반으로 계산합니다. 훈련시에 Training set을 사용했기 때문에, Training set을 추론하면 결과가 좋게 나옵니다. Validation set은 모델이 아직 알지 못하는 데이터이기 때문에 실제 상황과 더욱 비슷하다고 할 수 있습니다.
- What is SGD?
SGD(Stochastic Gradient Descent)는 경사하강법이라고도 불립니다. 함수를 따라 가면서 최적해를 찾는 방법입니다. 파라미터 값의 미분의 방향과 크기에 따라 손실을 최소화할 수 있는 방향으로 파라미터를 재조정합니다.
- Why does SGD use mini-batches?
Full-batch는 시간이 오래걸리고, 하나의 행만 사용하여 SGD를 수행하면 오류가 커질 수 있기 때문입니다. 따라서 mini-batches를 활용해 평균 손실을 계산하는 방법을 사용합니다.
- What are the seven steps in SGD for machine learning?
- 파라미터 초기화
- 예측값 계산
- 손실 계산
- 미분 계산
- 파라미터 조정
- 재훈련
- 손실이 기준점 이하로 정해지거나 반복 횟수에 도달하면 훈련 종료
- How do we initialize the weights in a model?
무작위적으로 값을 지정합니다.
- What is “loss”?
Loss는 예측값과 실제값을 입력 받아 지정한 수식에 따라 계산한 손실입니다. 손실(Loss)이 적을수록 유효한 예측을 한다고 말할 수 있습니다.
- Why can’t we always use a high learning rate?
높은 학습률은 모델이 최적값을 찾지 못하고 튕겨져 나가기도 합니다. 따라서 작은 학습률에서 시작하여 높여가거나, 학습률 발견자를 사용하는 것이 좋습니다.
- What is a “gradient”?
gradient는 기울기, 미분값이라고 할 수 있습니다.
딥러닝에서는 얼마나 파라미터를 조정해야 손실이 적어질지 알려주는 역할을 합니다.
- Do you need to know how to calculate gradients yourself?
그렇지 않습니다. pytorch에서 requires_grad_를 True로 지정하고, backward()를 호출하면 계산됩니다.
- Why can’t we use accuracy as a loss function?
정확도는 학습에 따라 개선되는 정도가 미미할 수 있습니다. 정확도가 개선되지 않는 경우 해당 지점의 미분값은 ’0’이고, 이는 학습이 되지 않게 합니다.
그래서 보통 loss function은 완만한 곡선의 모양을 사용합니다.
- Draw the sigmoid function. What is special about its shape?
import torch
import matplotlib.pyplot as plt
x = torch.linspace(start=-2, end=2, steps=100)
y = torch.sigmoid(x)
plt.plot(x, y)
plt.title('Sigmoid')Text(0.5, 1.0, 'Sigmoid')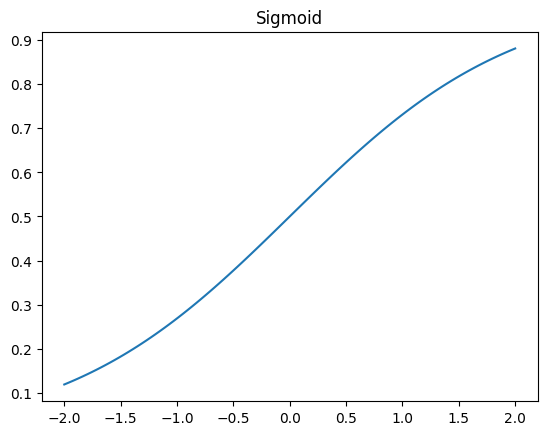
0과 1 사이에서 완만히 증가하는 곡선입니다. 모든 곳에서 미분을 구할 수 있습니다.
- What is the difference between a loss function and a metric?
loss function은 컴퓨터가 모델을 최적화하기 위해 사용하는 것이고, metric은 사용자가 모델의 성능을 확인하기 위한 것입니다. loss function과 metric은 같을 수도 있고, 다를 수도 있습니다.
- What is the function to calculate new weights using a learning rate?
Optimizer의 step function으로 계산할 수 있습니다.
- What does the DataLoader class do?
DataLoader class는 Python의 collection 형태를 입력받아 mini-batch에 반복할 수 있게 초기화하는 클래스입니다.
- Write pseudocode showing the basic steps taken in each epoch for SGD.
for x, y in dl:
pred = model(x)
loss = calc_grad(pred, y)
loss.backward()
parameters -= parameters.grad * lr- Create a function that, if passed two arguments [1,2,3,4] and ‘abcd’, returns [(1, ‘a’), (2, ‘b’), (3, ‘c’), (4, ‘d’)]. What is special about that output data structure?
x = [1,2,3,4]
y = 'abcd'def func(x,y): return [(i, j) for (i, j) in zip(x, y)]func(x, y)[(1, 'a'), (2, 'b'), (3, 'c'), (4, 'd')]튜플을 원소로 가지는 리스트입니다.
- What does view do in PyTorch?
import torch
ts = torch.tensor(range(9))
tstensor([0, 1, 2, 3, 4, 5, 6, 7, 8])ts.view((3,3))tensor([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])torch.tensor.view는 tensor의 shape를 변환합니다.
- What are the “bias” parameters in a neural network? Why do we need them?
bias는 편향항으로도 불립니다. neural network에서 bias term이 없을 때, 입력이 0이면 항상 0입니다. bias는 입력이 0이더라도 값 차이를 만듭니다.
- What does the @ operator do in Python?
@ 연산자는 decorator라고도 불립니다. decorator는 function을 함수로 받아 실행하는 function입니다.
def make_pretty(func):
def inner():
print('I got decorated')
func()
return inner@make_pretty
def ordinary():
print('I am ordinary')
ordinary()I got decorated
I am ordinary- What does the backward method do?
backward는 미분값을 계산합니다. 미분값의 크기와 부호에 따라 loss 값을 줄이기 위한 방향과 강도를 알 수 있습니다.
- Why do we have to zero the gradients?
gradients는 계산마다 누적됩니다. 따라서 한 번 gradients를 계산하여 계수를 조정한 다음에는 gradients를 초기화 하여야 합니다.
- What information do we have to pass to Learner?
from fastai.vision.all import *DataLoaders, model, loss_function, opt_func를 필수 설정하고 metric 등을 추가 설정할 수 있습니다.
- Show Python or pseudocode for the basic steps of a training loop.
def train_model(epochs=100):
for _ in range(epochs):
coeffs = init_coeffs()
preds = calc_preds(indep, coeffs)
loss = calc_grad(preds, dep)
loss.backward()
with torch.no_grad():
coeffs -= loss.grad- What is “ReLU”? Draw a plot of it for values from -2 to +2.
import torch
x = torch.linspace(-2,2,100)
y = torch.clamp(x, min=0)
plt.plot(x, y)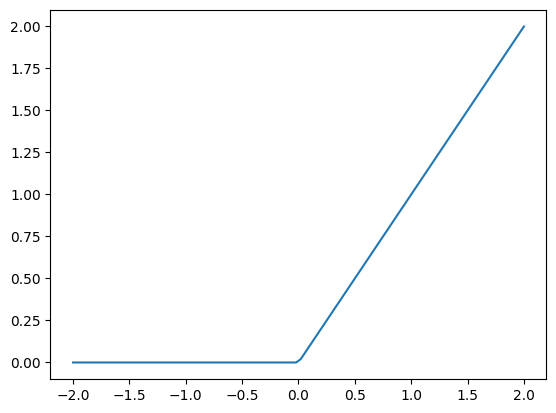
- What is an “activation function”?
Activation function은 신경망에서 비선형 문제를 풀기 위해 적용하는 함수입니다.
대표적으로 음수 값을 0으로 만드는 ReLU 함수가 있습니다.
- What’s the difference between F.relu and nn.ReLU?
F.relu는 자체의 함수, nn.ReLU는 pytorch 모듈의 종류입니다.
- The universal approximation theorem shows that any function can be approximated as closely as needed using just one nonlinearity. So why do we normally use more?
경험적으로 여러 계층을 사용할 때 모델이 더욱 적합되는 것을 발견했습니다.